
How DRM3 Uses Decentralized AI to index the World's News
Stake to get inference. Open models, no lock-in, no spend.
Decentralized AI uses open-weight models, handles processing and ops for you, and uses stake-based tokenomics to power the network. You stake tokens and get inference. You do not spend. Your stake stays yours.
Stake, don't spend Your tokens stay yours. Capex, not opex.
No vendor lock-in Switch models and providers freely.
No training on your data Privacy by default.
Permissionless No approval, no waitlist, no terms changes.
Uncensored Open-weight models, no content filtering.
Open models closing in Competitive with flagships across benchmarks.
Broad selection 20+ models, not one provider's proprietary model.
Marketplace economics Providers meet consumers at market price.The news scan behind TruthFoundry is DRM3's article analysis pipeline. It processes thousands of articles daily, each requiring 8,000 to 12,000 tokens of structured AI analysis: entity extraction, topic classification, sentiment, provenance metadata. The pipeline cascades across decentralized providers and Cloudflare Workers AI as a fallback. Here is the breakdown.
Over 100 million tokens per day of AI inference at near-zero daily cost. Venice DIEM and MOR (mordiem.com) are staked, not spent. Cloudflare Workers AI is metered but stays near the free tier at current volume. The capital is locked, not consumed. Stake once, run indefinitely.
News analysis is a natural fit for decentralized inference. The input is public data (published articles). The prompts are not sensitive (structured extraction templates). The output is a markup pass: entity extraction, topic classification, sentiment scoring, provenance metadata. These get stored for search and embedded for semantic retrieval. Open-weight models handle this well. The task is structured, the data is public, and the results are deterministic enough that model variance is a non-issue.
Venice and Morpheus are both moving toward TEE (Trusted Execution Environment) support for workloads that do require confidentiality. For this use case, the open model path is already ideal.
Venice DIEM
DIEM is a token on Base that provides access to the Venice AI API. 1 DIEM staked = $1/day of compute, resetting at UTC midnight. Venice serves 20+ models through a standard OpenAI-compatible API.
Venice DIEM handles the bulk of DRM3's inference volume. The TruthFoundry news scan processes thousands of articles daily at 8,000 to 12,000 tokens each (see Ore to metal). The pipeline cascades across mordiem.com, Venice DIEM, and Cloudflare Workers AI, burning through each provider in order and falling to the next when capacity runs out.
Provider Tokens Calls Share
───────────────────────────────────────────────
VENICE ~84.4M ~9,200 84% 15 DIEM/day
WORKERS AI 10.3M 1,323 10% fallback
MORDIEM 6.4M 714 6% MOR subnet
───────────────────────────────────────────────
Total ~101.1M ~11,200Morpheus
Morpheus is an on-chain compute marketplace on Base. Providers register models, post bids, and serve inference over an encrypted TCP protocol. Consumers stake MOR to open sessions.
Pistachio
Pistachio is DRM3's client for the Morpheus marketplace. It handles session lifecycle, staking, model selection, and provider communication. See Pistachio v0.30 for the latest release, or Pistachio: Peer-to-Peer AI Inference on the Morpheus Network for an overview.
When more providers come online, Pistachio will use them without any changes.
mor.org provider benchmarks
DRM3 runs daily throughput audits against the Morpheus marketplace using `pistachio benchmark` (see Pistachio v0.30). Current results against the mor.org provider:
max_tokens Requests Success Avg Latency Best Models
────────────────────────────────────────────────────────────
250 73 100% 3.4s all 4 models
500 49 97% 4.6s qwen3-next-80b, glm-4.7
750 20 90% 7.5s qwen3-next-80b, glm-4.7
1,000 4 0% timeout noneModel Success Latency Tokens/req
─────────────────────────────────────────────────────
qwen3-next-80b 100% 3.3s 503
venice-uncensored 100% 5.0s 1,013
glm-4.7 100% 5.0s 473
mistral-31-24b 83% 7.3s 514mor.org provider ceiling: completions above 920 tokens fail. Under heavy concurrent load, the provider degrades with 120-second timeouts and empty responses. Interactive chat under 500 tokens works well. Bulk analytical workloads are not viable on this provider today.
mordiem.com
mordiem.com is a Morpheus subnet. Stake MOR into the subnet, get a Venice-backed API key. The operator takes the capital yield and uses it to fund Venice inference on your behalf. You get quality API access for staking MOR, roughly 2.5x less expensive than staking DIEM directly.
DRM3 began incorporating mordiem.com into its inference cascade on June 1, 2026. Currently about 6% of estimated daily token volume. Processing at Venice capability with a negligible ~2% latency difference from the added hop.
DRM3 provider node (drm3.network)
DRM3 experimented with running its own Venice DIEM-backed Morpheus provider. Five models registered on-chain, ECIES-encrypted TCP, 100% success rate across 432 benchmark requests at up to 4,000 tokens per completion. The node is no longer active, but the on-chain record remains on the Cashew explorer.
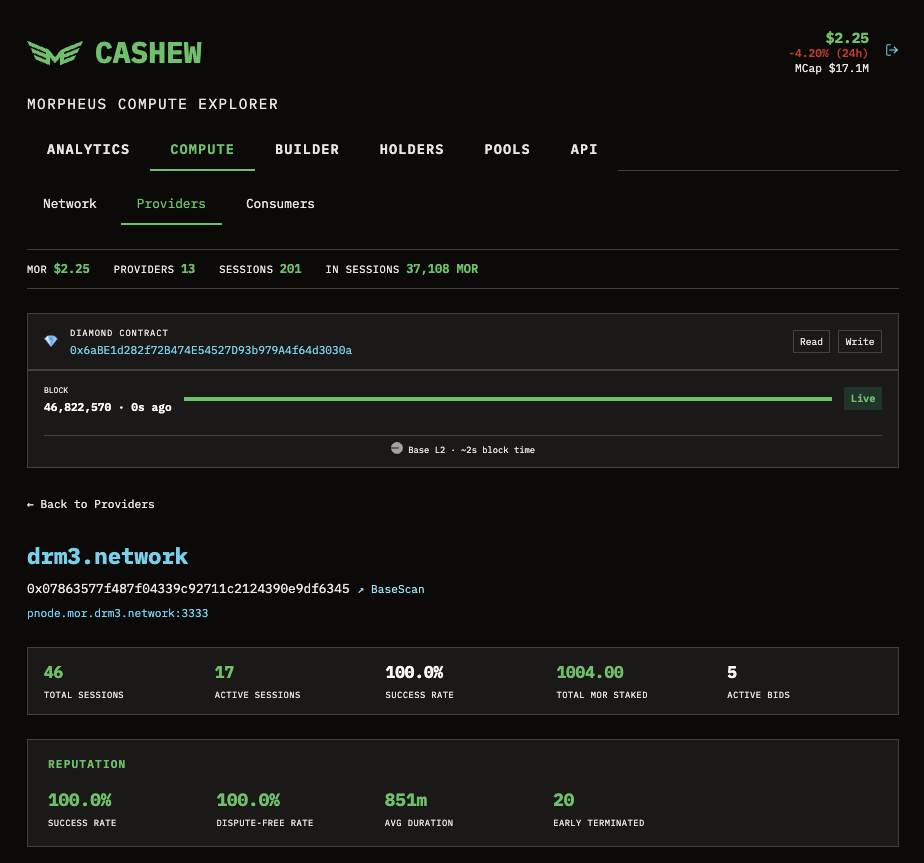
Address 0x07863577f487f04339c92711c2124390e9df6345
Endpoint pnode.mor.drm3.network:3333
Status offline
Sessions 46 total · 17 active
Success 100.0%
Disputes 0 (100% dispute-free)
Avg Dur 851 minutes
Staked 1,004 MOR
Bids 5 active modelsRequests 432
Failures 0
Lanes 16 concurrent
Tokens 1,000 – 4,000 per completion
Models llama-3.3-70b · venice-uncensored · glm-4.7
mistral-31-24b · qwen3-next-80bDisclosure: DRM3 Labs holds and stakes MOR and sells MOR-denominated products.
Published by
Robert Christian
Founder and CEO, DRM3 Labs Corp.
More from DRM3 Labs
DomainDrift 1.86: alerts reach your channel, and a parked domain is a reading too
Robert Christian · 3 min read
TruthFoundry 1.12: see what carries a claim and what cuts against it
Robert Christian · 2 min read
TruthFoundry 1.11: check a claim, read the verdict in seconds
Robert Christian · 2 min read
2026 DRM3 Labs Corp. All rights reserved. DRM3 Labs builds infrastructure for open protocols.
This article is for informational purposes only. Nothing here is financial, investment, or legal advice. Tokens, staking, NFTs, and blockchain protocols are described as technical mechanisms, not investment recommendations. Digital assets carry risk. Do your own research.
Many DRM3 products mentioned are in early alpha. Features, availability, and economics are subject to change. References to the Morpheus network describe the public protocol as documented at mor.org.